Это - список программ и учебно-методических материалов по анализу заболеваемости для эпидемиологов и научных работников с сайта 1mgmu.com
Увеличить шрифт ::
Уменьшить шрифт
Программа анализа частот и построения графика в стиле доказательной медицины
НАЗНАЧЕНИЕ: Расчет доверительных границ к набору частот и построение графика в стиле доказательной медицины.
ИСХОДНЫЕ ДАННЫЕ: Набор пар «Число наблюдений и число успешных наблюдений», то есть тех, в которых было зафиксировано интересующее нас событие.
Например, при оценке летальности число наблюдений – количество пациентов, а число успешных наблюдений – количество покойников.
ПОДРОБНОЕ ОПИСАНИЕ: Расчет частот и точных доверительных границ к частотам при произвольном уровне статистической значимости p, определение достоверности различий частот при попарном сравнении частот, проверка гетерогенности, построение графика в стиле т.н. «доказательной медицины».
ТЕХНИЧЕСКИЕ ОГРАНИЧЕНИЯ И ОБЛАСТЬ ПРИМЕНИМОСТИ: Используются точные формулы, применение которых при числе наблюдений более 1000 может приводить к ошибкам типа переполнения. В этом случае или работа программы заканчивается аварийно, или выдается сообщение о невозможности проведения расчета, или в качестве границ доверительных интервалов появляются невозможные значения: 0 или 1. В этом случае надо воспользоваться другими вариантами, см. ниже.
Рекомендуется попробовать провести расчет для имеющихся данных даже для случая больших чисел. Изначально программы писались для клиницистов и ориентировались на характерный для них объем данных, далее, в связи с появлением многоцентровых исследований, в программы добавляется обработка варианта больших объемов.
Работа над программами не прекращается, версии обновляются.
ДРУГИЕ ВАРИАНТЫ РЕШЕНИЯ: Доверительные границы для случая больших чисел можно рассчитать в Excel, смотри КАК РАССЧИТАТЬ ДОВЕРИТЕЛЬНЫЕ ГРАНИЦЫ К ЧАСТОТЕ ПРИ БОЛЬШОМ КОЛИЧЕСТВЕ НАБЛЮДЕНИЙ.
ИСПОЛЬЗОВАНИЕ.
Шаг 1. Перейти по ссылке https://1mgmu.com/progi1/www-risk.aspx
В результате видим следующее:

В верхней части мы видим таблицу с настройками. В левой части таблицы – выбор разделителя. По умолчанию разделитель – пробел, но могут быть случаи, когда этот вариант неудобен, например, если название группы – несколько слов, разделенных пробелом. В этом случае в качестве разделителя можно выбрать запятую или точку с запятой.
В правой части таблицы – величина статистической значимости р. Ее можно поменять на другую.
В следующее поле нужно ввести данные в следующем формате:
Каждая группа – отдельная строка. Для группы надо ввести ее название, общее количество наблюдений и количество «успехов», то есть в каком количестве наблюдений было интересующее нас событие.
Пусть, например, у нас есть три группы больных деструктивным туберкулезом из 320, 130 и 204 пациентов, в которых пациентов с двусторонней деструкцией было соответственно 101, 35 и 101 человек.
Шаг 2. Введем данные:

Шаг 3. Нажмем на кнопку «Рассчитать»
Если есть ошибки, программа сообщит, в какой строке введенных данных имеются ошибки (например, число «успехов» больше числа наблюдений, или неправильный разделитель, или текст вместо числа…). Ошибку можно исправить и еще нажать на кнопку «Посчитать».
Если все хорошо, то появляется кнопка «Построить график» и заполняются поля ниже.
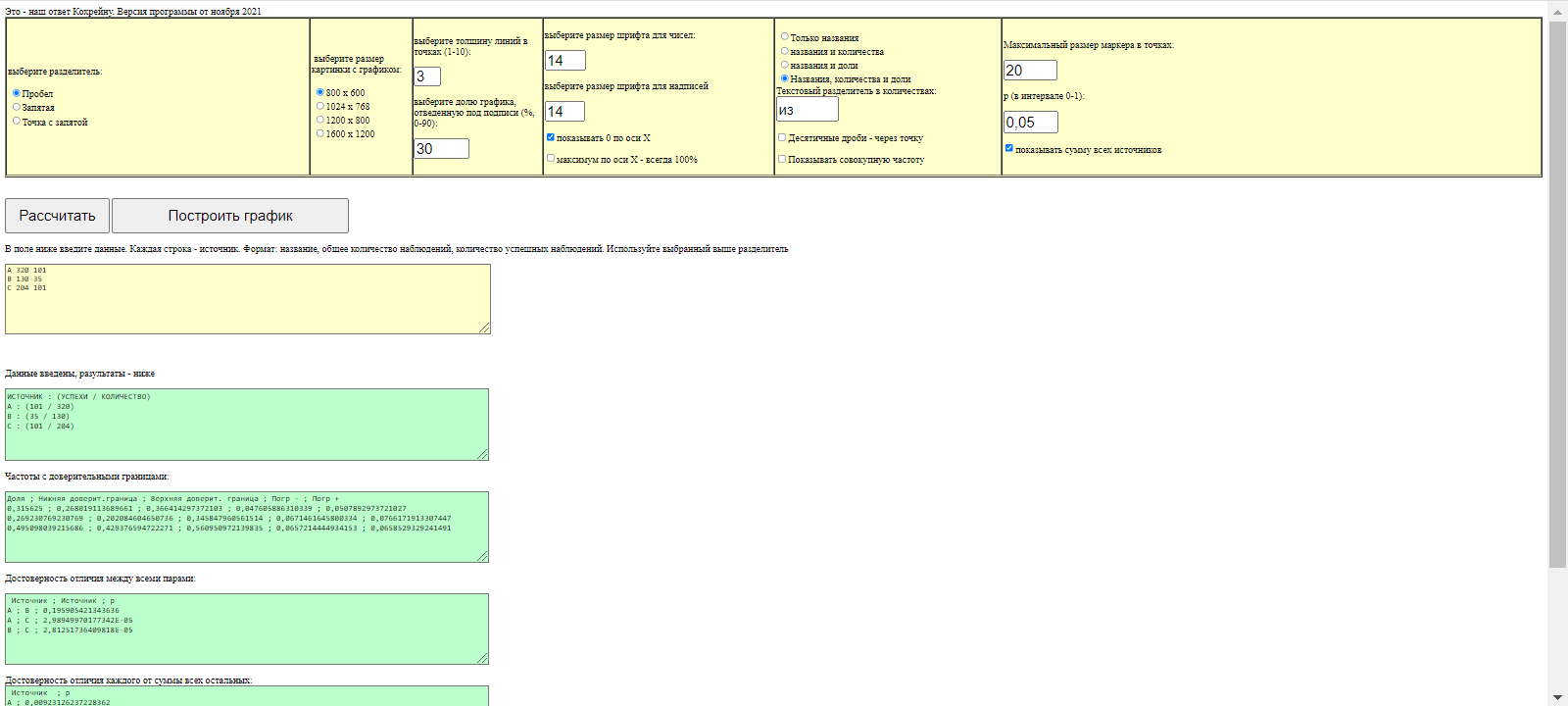
В следующем поле появляется информация о том, какие данные введены:
В следующем поле – числовые данные о частотах и доверительных границах. В качестве разделителя используется точка с запятой. Эти данные можно выделить, скопировать и использовать в Excel для проведения расчетов и построения графика. О том, как превратить этот текст в таблицу, написано в инструкции к «Программа расчета доверительных границ для биномиального распределения».
Следующее поле – достоверность различия частот при попарном сравнении:
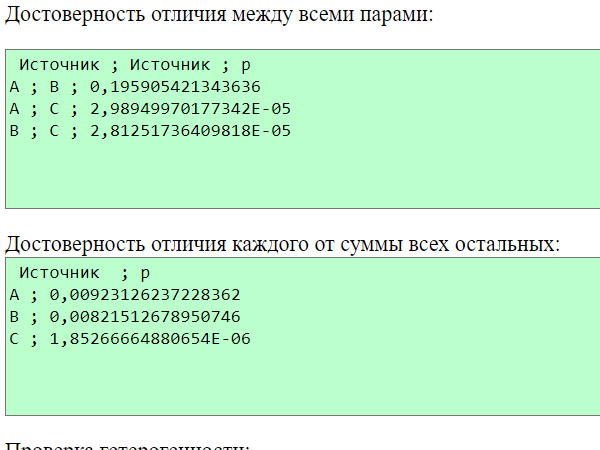
Здесь в строках – сравниваемые пары и достоверность отличия между ними.
Видно, что статистическая достоверность (значимость) при сравнении групп А и В равна 0,1959, то есть достоверных различий нет. А вот в группе С двусторонних вариантов достоверно больше, например, число 2,989Е-05 – это экспоненциальная форма записи числа 0,00002989.
Следующее поле – аналогичное сравнение каждого варианта с суммой всех остальных.
Последнее поле – проверка гетерогенности.

Полученная общая величина «хи-квадрат» - 23,46. Так как вариантов 3, то число степеней свободы равно 2, в результате чего получаем наличие достоверности различий с р<0,001.
Далее идет анализ устойчивости – какая будет величина «хи-квадрата», если по очереди исключать все варианты.
Анализ гетерогенности и устойчивости нужен при метаанализе.
Шаг 4. Нажмем на кнопку «Построить график»:
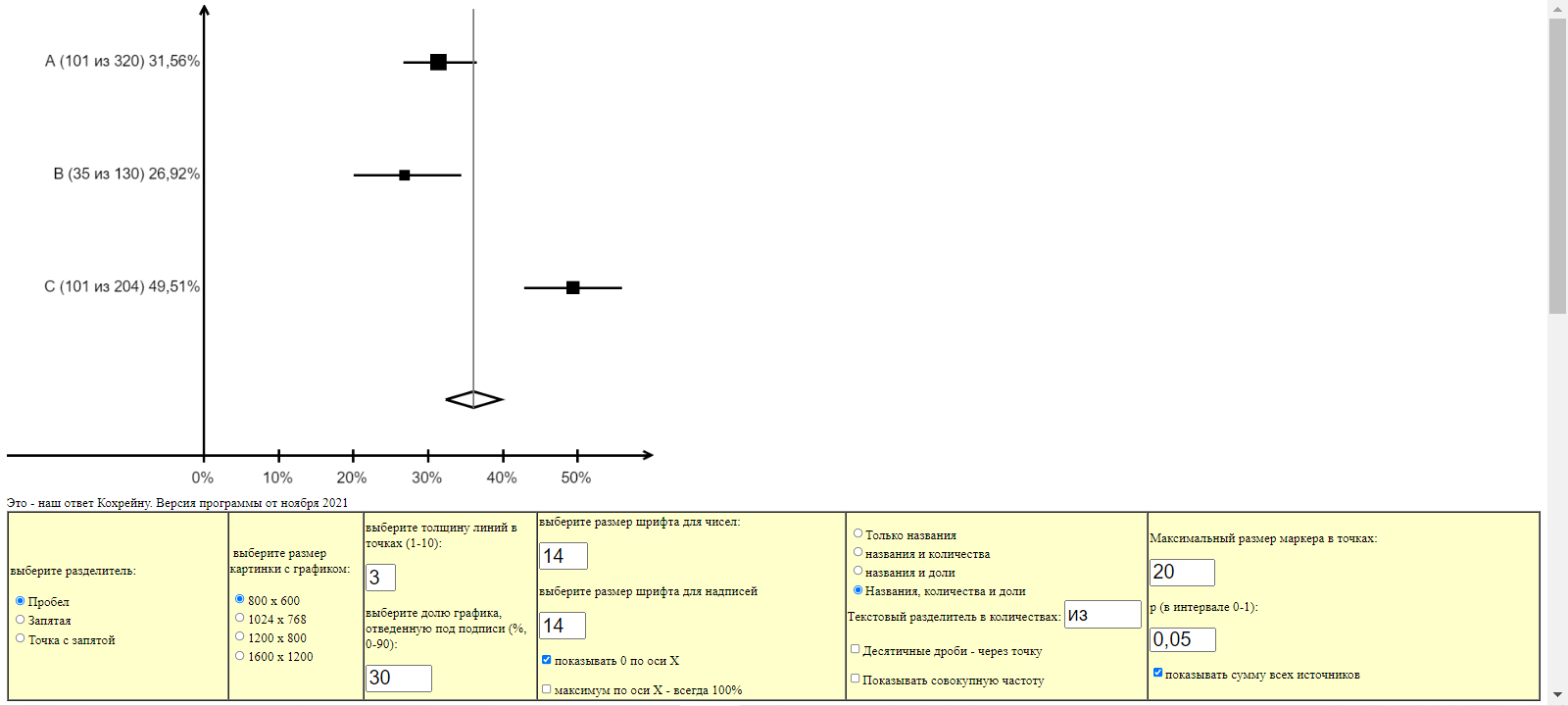
Квадратики показывают фактическую частоту, площадь квадрата пропорциональна размеру группы. Горизонтальная «палка» - доверительные границы для частоты. Вертикальная серая линия показывает совокупную частоту, то есть какова будет частота событий, если все группы объединить в одну, а ромб – доверительные границы для совокупной частоты.
В левой части графика – подписи с названием группы, числом наблюдений и успешных наблюдений в ней, а также частотой. На таблице настроек параметров построения графика есть переключатели, которые позволяют выбрать нужный вариант подписей:
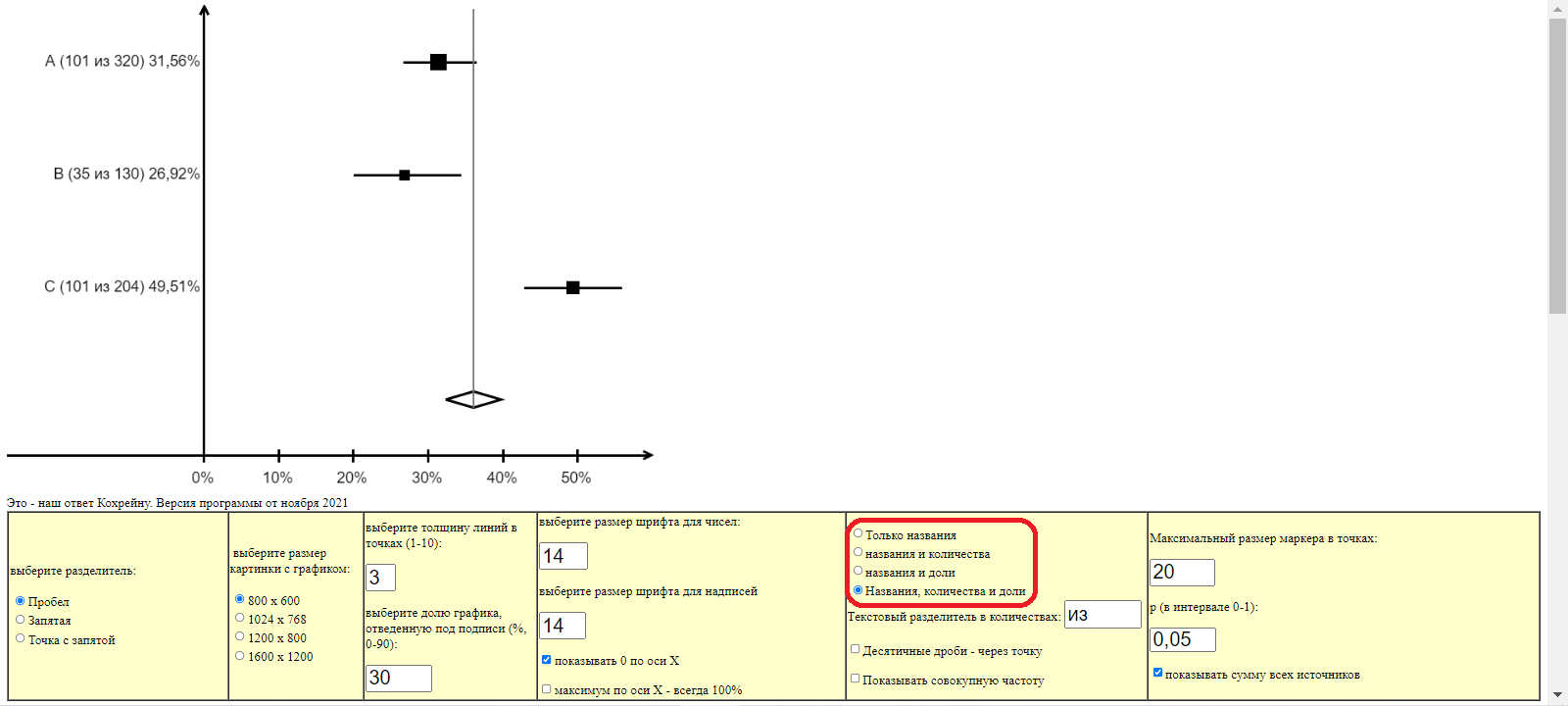
Шаг 5 Улучшайзинг полученного графика
Будем делать график для вставки в статью. Для получения рисунка максимального качества выберем максимальный размер рисунка и нажмем кнопку «Построить график»:
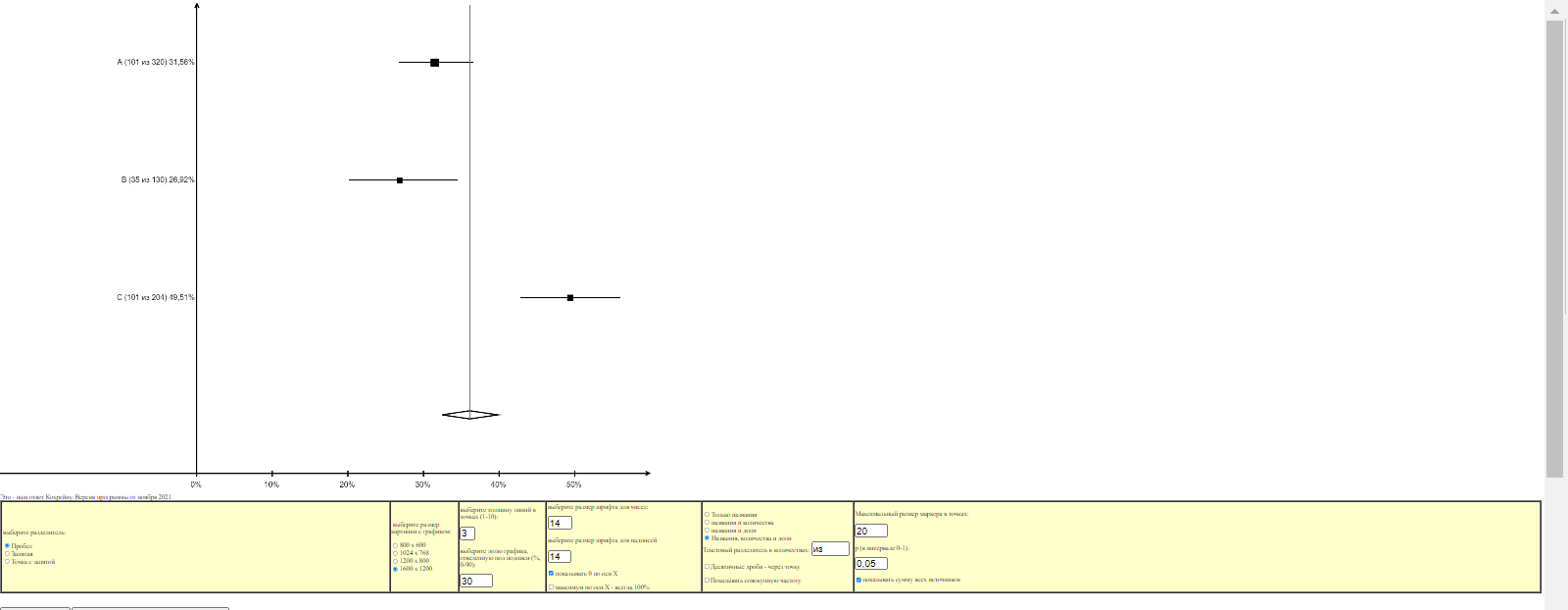
После этого поменяем размер шрифта для подписей и чисел с 14 до 32, толщину линий с 3 до 5 и максимальный размер маркера до 40 и опять нажмем кнопку «Построить график»:
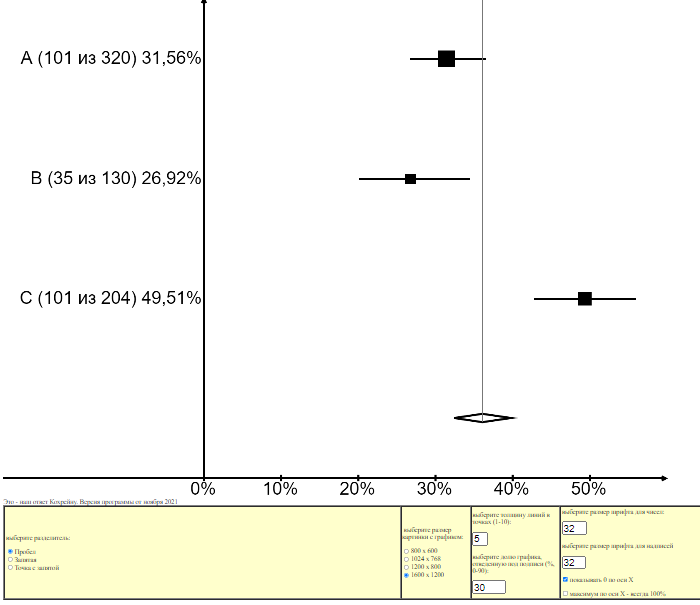
Теперь отметим «Показывать совокупную частоту» и уменьшим долю графика, отводимую под подписи, с 30 процентов до 22. Еще раз строим график:
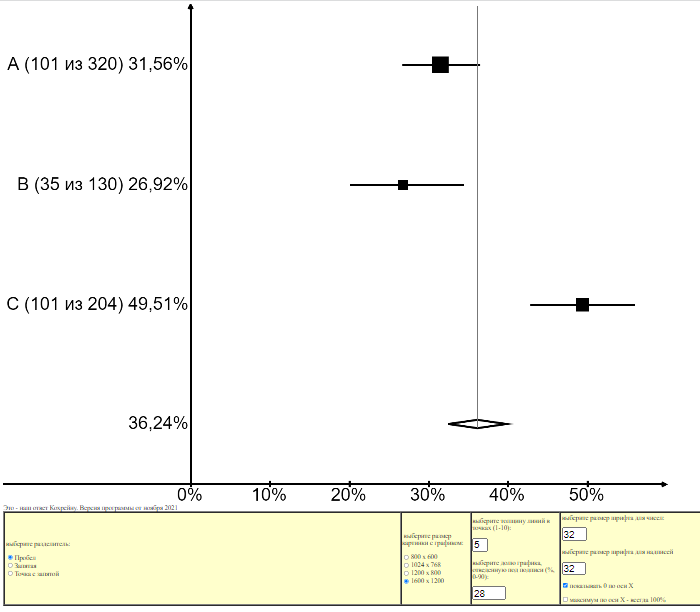
Шаг 6 Сохранение графика
Щелкнем в середину графика правой кнопкой мышки и выберем команду «Сохранить рисунок как»:
В качестве типа сохраняемого файла лучше всего выбрать png. Далее выбираем нужную папку и меняем название файла.
Сохраненный в виде файла рисунок можно вставить в документ Word командой Вставка/Рисунок
В результате видим следующее:
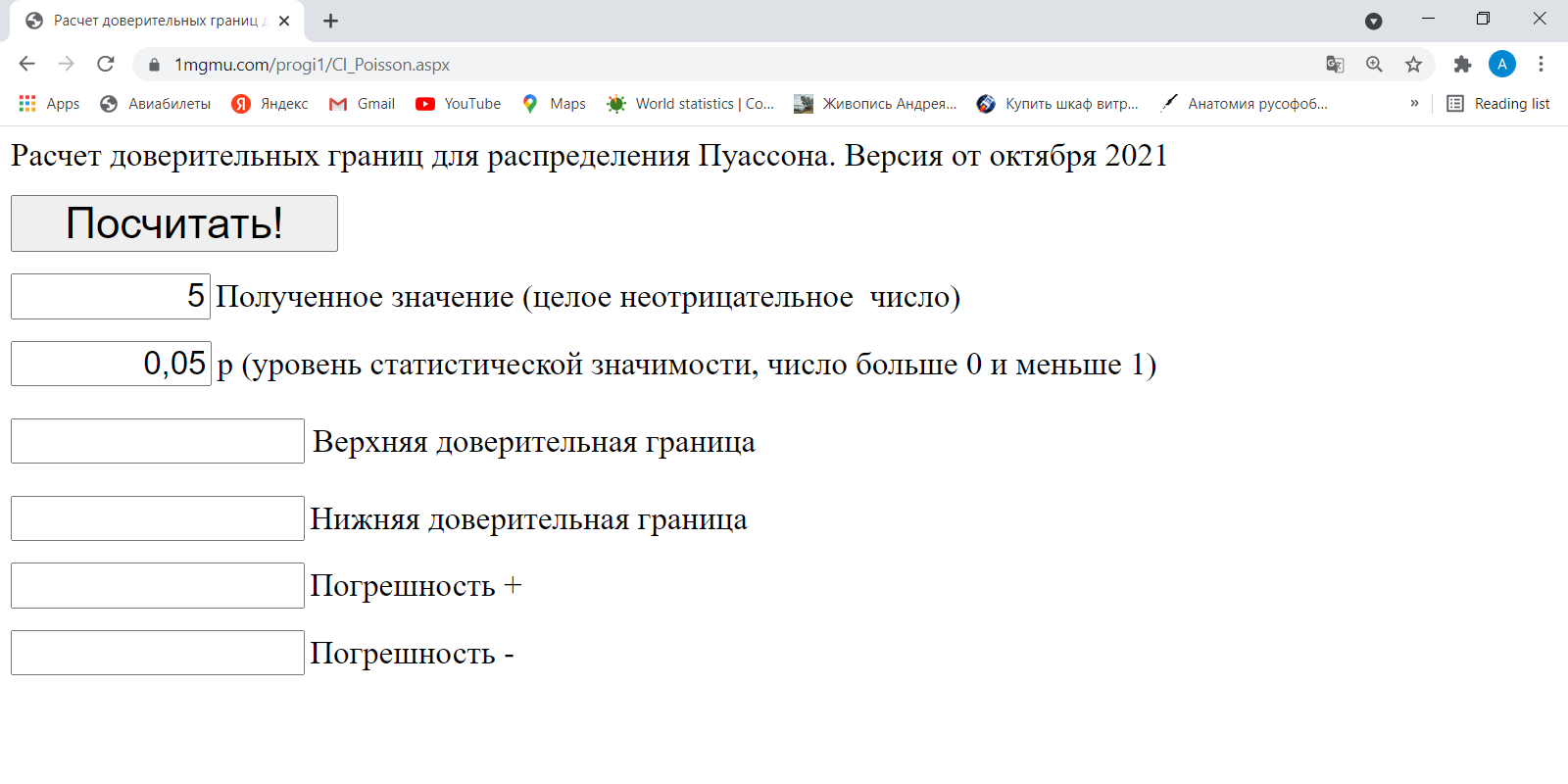
Шаг 2. Вводим нужное число событий. Например, в Москве 1 ноября 2021 года от Covid-19 умерло 96 человек:

Шаг 3. Нажимаем кнопку «Посчитать». Получаем следующее:
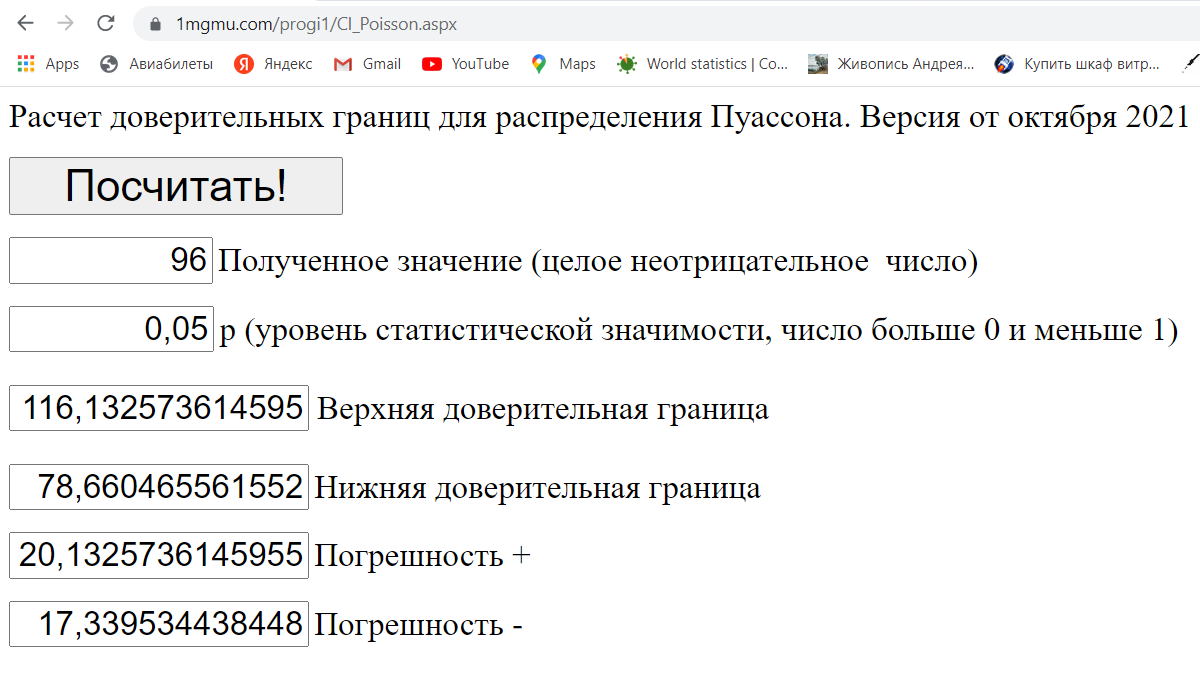
Полученные числа можно выделить и скопировать.
В данном случае получили, что (при р=0,05) 96 смертей за день можно ожидать при среднедневном количестве смертей от 78,66 до 116,13.
Следующие два поля обозначены как «Погрешность +» и «Погрешность -». Это - разность между фактическим количеством случаев и его верхней и нижней доверительной границей. Названия «Погрешность +» и «Погрешность -» использованы потому, что эти величины под такими названиями часто используются в Excel при построении полос погрешности на графиках.
Так как официальная численность населения Москвы 12655050 человек, то смертность на 100 тыс. человек составляет 96×100000/126550500,759 с доверительными границами от 78,66×100000/126550500,622 до 116,13×100000/126550500,918.
В том случае, если число случаев достаточно велико, можно рассчитывать доверительные границы в Excel по приближенным формулам. Делается это следующим образом:
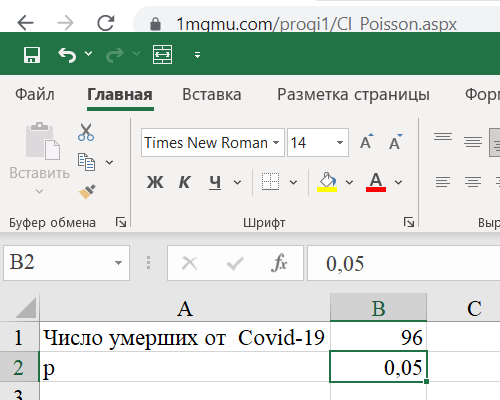
Шаг 1. Вводим число случаев и p:
Шаг 2. Для расчета t вызываем мастера функций и выбираем категорию «Статистические»:
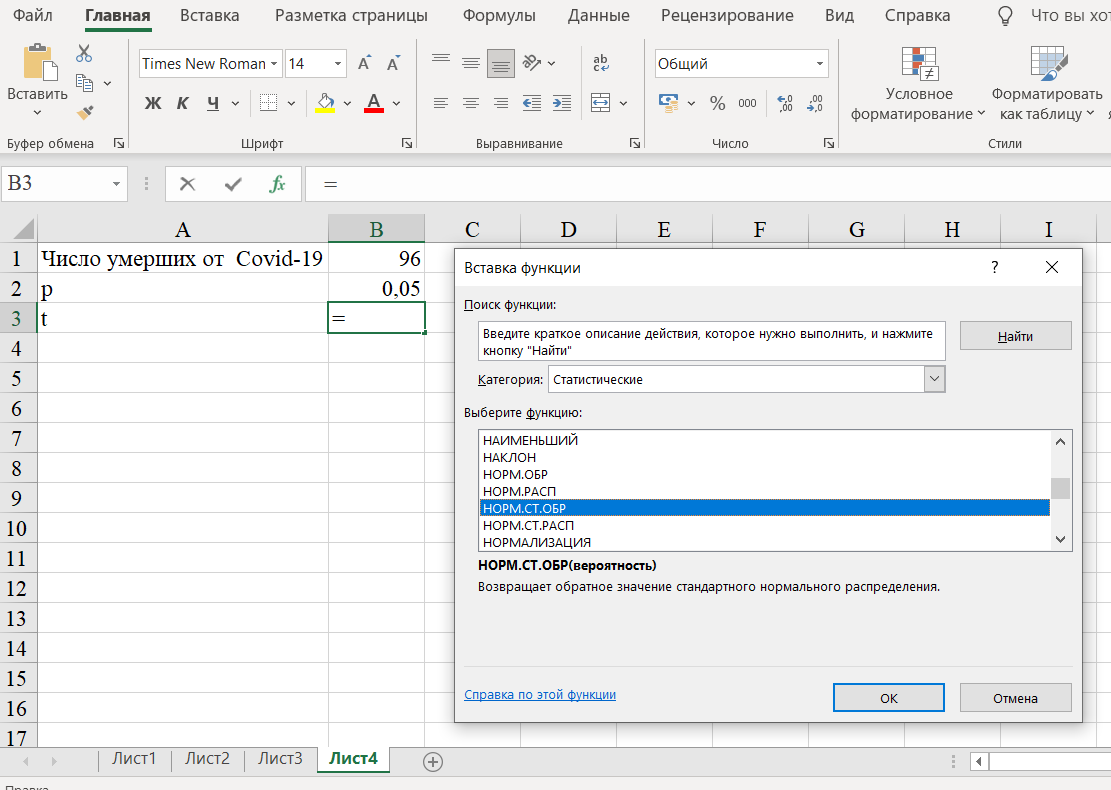
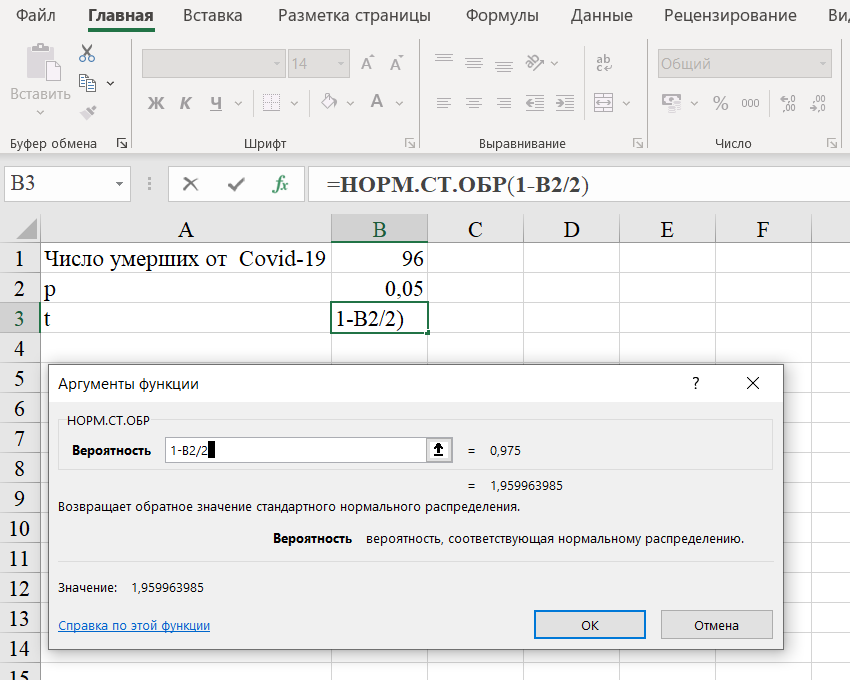
Шаг 3. Выбираем функцию Нормстобр. В качестве вероятности выбираем 1-р/2:
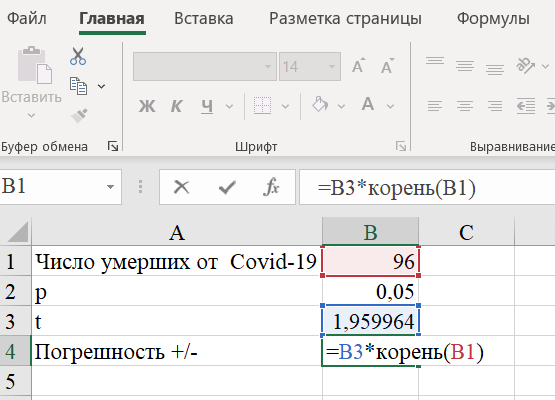
Шаг 4. Рассчитываем погрешности +/- (для приближенной формулы они совпадают):
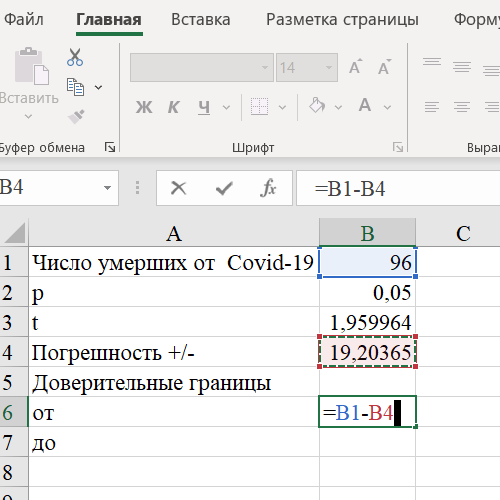
Шаг 5. Рассчитываем доверительные границы. От:
Шаг 6. До:
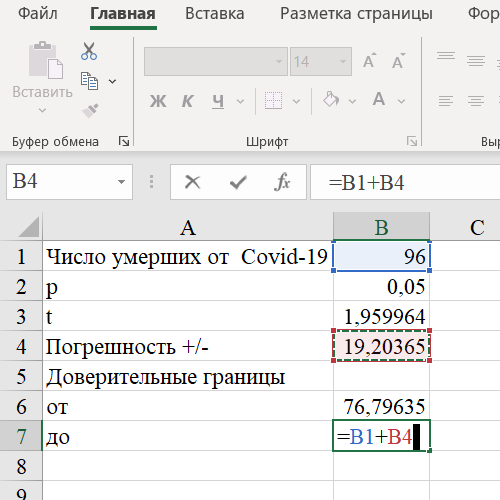
Видно, что для данного случая использование приближенных формул приводит к погрешности при определении доверительных границ на уровне менее 2%.
Шаг 7. В случае необходимости можно перевести количество случаев в частоту или интенсивную заболеваемость. Например, для определения летальности на 100 тысяч совокупного населения умножим число случаев на 100 тысяч и разделим на численность населения Москвы:
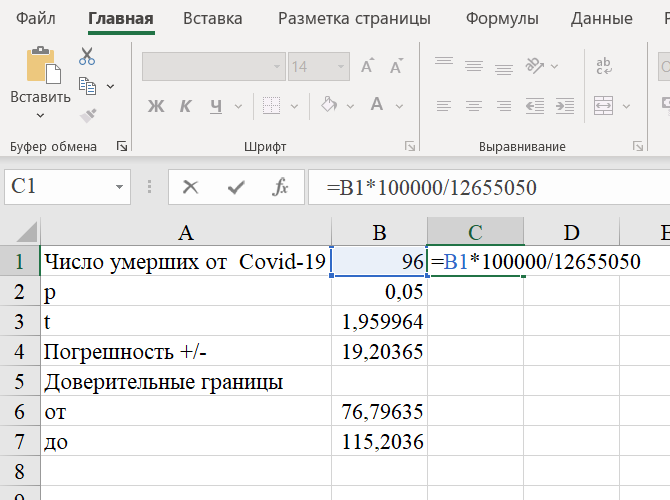
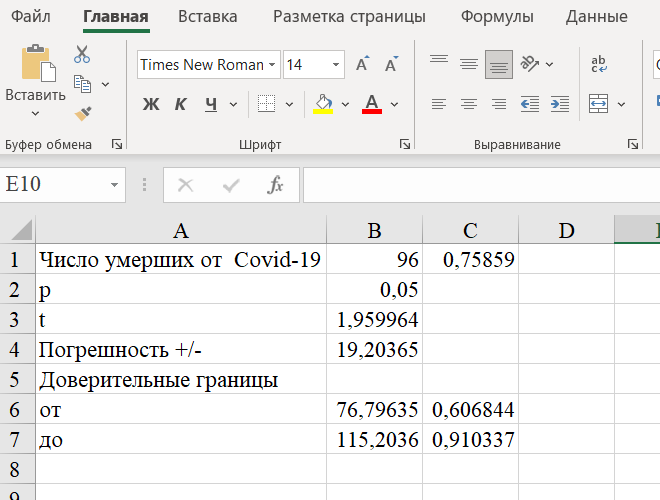
Шаг 8. Скопируем ячейку C1 в ячейки С6 и С7
НА ГЛАВНУЮ СТРАНИЦУ САЙТА